1 min to read
엔디안

안녕하세요. chanos입니다. 😉
오늘은 엔디안에 대한 글입니다.
💡 개념
컴퓨터가 데이터를 저장하는 최소 단위는 바이트인데, 바이트가 저장되는 순서를 byte order라고 부르고 이러한 byte order가 어떤 순서로 저장되는지에 따라 빅-엔디안과 리틀-엔디안으로 구분이 됩니다.
메모리에 값이 저장될 때 메모리의 주소는 낮은 곳에서 높은 곳으로 저장이 됩니다.
메모리 주소의 낮은 곳 부터 데이터가 저장될 때 가장 큰 데이터 부터 저장되는 방식의 아키텍처를 빅-엔디안이라 칭하고 가장 작은 데이터 부터 저장되는 방식을 리틀-엔디안이라 칭합니다.
예를 들어 데이터가 0x12345678인 경우 다음과 같이 데이터가 저장됩니다.
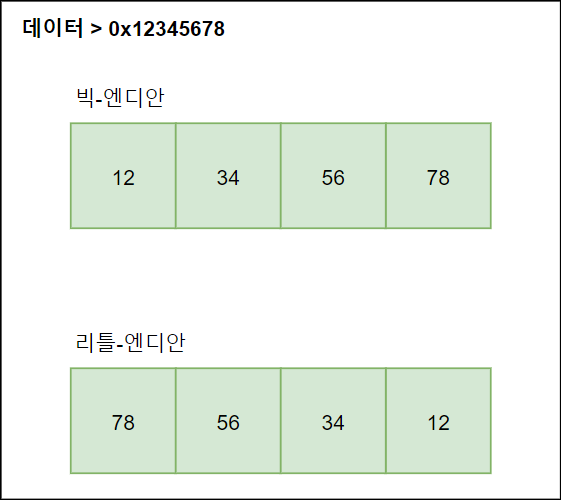
이렇게 엔디안에 따라 데이터가 저장되는 순서가 다른데 여기서 문제점이 발생합니다.
한 피시에서 애플리케이션을 실행하여 데이터를 쓰는 경우 읽기/쓰기 방식이 같기 때문에 크게 상관은 없지만 서로 다른 기종간에 네트워크 통신을 할 때 입니다.
클라이언트 PC는 리틀-엔디안을 사용하고 서버 PC는 빅-엔디안을 사용하는 경우, 클라이언트 PC에서 데이터를 전달할 때 서버PC에서 전혀 다른 데이터를 받아올 수 있기 떄문입니다.
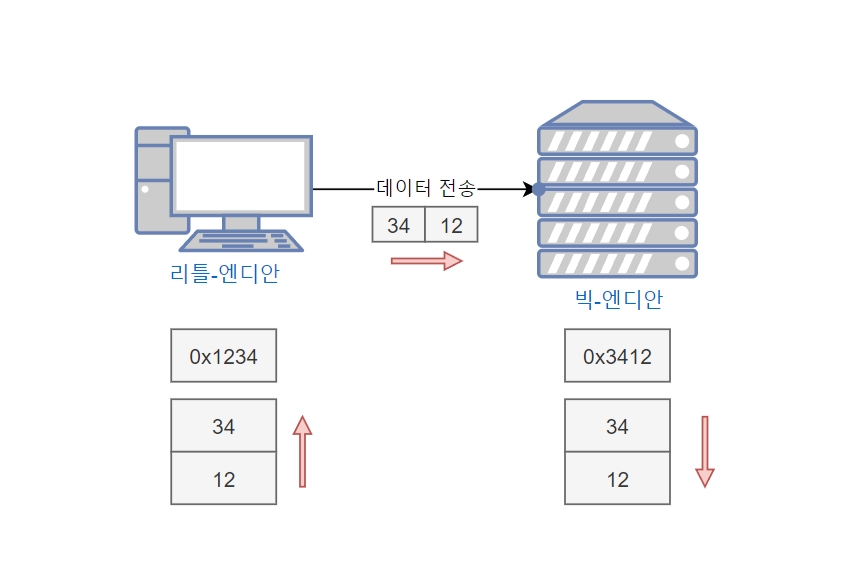
위와 같이 클라이언트 PC에서는 리틀-엔디안 방식을 이용하는 경우 데이터가 34, 12 순서로 되어있기 때문에 이 데이터를 통신할 때 그대로 보내게 된다면 빅-엔디안을 사용하고 있는 서버PC에서는 받아온 데이터를 그대로 메모리 상에 저정하기 때문에 0x3412라는 엉뚱한 값이 될 수 있습니다.
이러한 문제점 때문에 네트워크 통신에서의 byte order에 대한 표준이 필요하게 되었고 네트워크 통신 시 사용하는 byte order는 빅-엔디안으로 채택됐습니다.
그렇기 때문에 네트워크 통신 시 리틀-엔디안이면 빅-엔디안으로 데이터를 컨버트해서 전송해야 합니다.
대표적으로 빅-엔디안을 사용하는 CPU는 SPARC, ARM, Motorola 계열이고 리틀-엔디안을 사용하는 CPU는 x86, 인텔 계열이 있습니다.

