ES ElasticSearch (2)
ElasticSearch 구조
Posted 
By
2 min read
- 목차
- ES 윈도우 ElasticSearch 설치
- ES ElasticSearch (1)
- ES ElasticSearch (2) 👈
- ES ElasticSearch (3)
ElasticSearch Structure 🛠
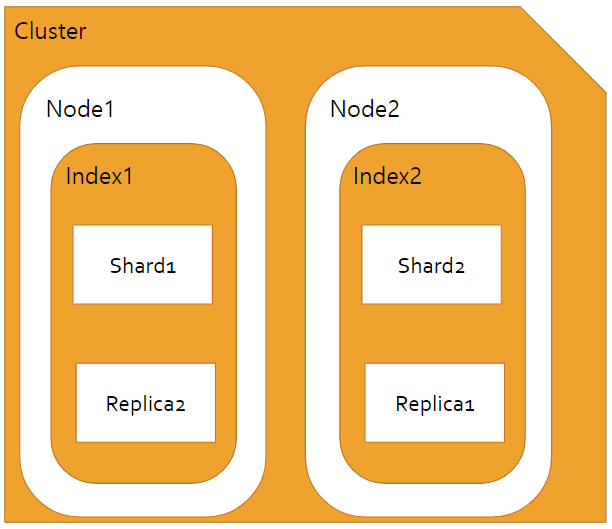
Cluster- ElasticSearch에서 가장 큰 시스템 단위이다.- 최소 하나의 노드로 이루어진 집합
- 서로 다른 클러스터는 독립적인 시스템으로 유지되고, 한 서버에서 여러 개의 클러스터가 존재할 수 있다.
Node- 데이터를 색인하고 저장, 검색을 수행하는 단위 프로세스이다.- ElasticSearch.bat을 실행하면 하나의 Node Instance를 실행하는 것이다.
- Defalut Node는 기본적으로 Master이면서 Data역할도 수행한다.
- 클러스터에 노드가 추가되면 Shard가 재분배 된다.

- 크게 Master Node와 Data Node로 구분
- Master Node - Cluster 정보 관리
- Data Node - 색인된 데이터 저장
Index- 데이터가 저장되는 논리적 공간이다.- 하나의 Index는 하나의 type(_doc)를 가지며 최소한으로 1개의 primary shard를 갖는다.
- 한 index에 같은 primary shard와 replica shard가 존재할 수 없다.
- 하나의 Index는 하나의 type(_doc)를 가지며 최소한으로 1개의 primary shard를 갖는다.
Shard- 일종의 파티션과 같은 의미, 데이터 그 자체이다.- Index를 생성할 때 7.x버전 부터는 Default로 1개의 Shard로 인덱스가 구성된다.
- Shard는 Primary shard와 Replica shard로 구분된다.
Primary shard- documents가 indexing될 때 하나 이상의 파티션에 저장되는데 이 파티션이 primary shard이다.Replica shard- 각 primary shard의 복사본을 의미한다. 해당 primary shard가 장애가 났을 경우 이 replica shard가 역할을 대신 수행한다 (고가용성)
This post is licensed under CC BY 4.0 by the author.